While working in a limited memory environment I needed to be frugal with the amount of RAM a package would take up. To this end, I had a Slowly Changing Dimension that contained about a million records, which when running on a 32 machine would crash and run out of memory part-way through.
This also applied to large transformations, where although I didn't run out of memory, going to capacity greatly slowed the process down.
What I found to ease these troubles is the Modulo Algorithm. By using this to split the data, or in the case of the dimension to process smaller chunks, is that performance and in fact the ability to complete the processing at all was greatly improved!
Here's an example of how to implement it in a simple enough Slowly Changing Dimension:
Let's start with the data. A large dimension of changing size (new records can be added at anytime - especially with a customer, client or address dimension). Limited RAM (2GB per transaction) with an optimal and easily controlled 10,000 records processed with each iteration.
I will use a For Loop Container to loop through each iteration. To work out the number of iterations I will divide the number of records in the dimension by 10,000 and round this UP to the nearest integer.
We want to create a table in our database that will hold each iteration of records - I make this table on the fly each time, so I can use it for multiple packages and tables.
Drag an Execute SQL Task onto the DataFlow and set the ResultSet to 'None'. Set the SQL to the following:
If (EXISTS (SELECT * FROM INFORMATION_SCHEMA.TABLES
WHERE TABLE_SCHEMA = 'dbo'
AND TABLE_NAME = 'Modulo_Temp'))
BEGIN
DROP TABLE dbo.Modulo_Temp
END
ELSE
BEGIN
CREATE TABLE dbo.Modulo_Temp
(Field1 int,Field2 varchar(100))
END
The CREATE TABLE part of the query needs to match the structure of the relational table used to match to the existing dimension.
Create two variables called 'Iterations' and 'CurrentIteration' as below:
Drop a script task in to your Control Flow, add in the below SQL Statement, set the ResultSet to SingleRow and map the ResultSet to variable 'Iterations'.
select (count(ID) / 10000) + 1
from dbo.TableName
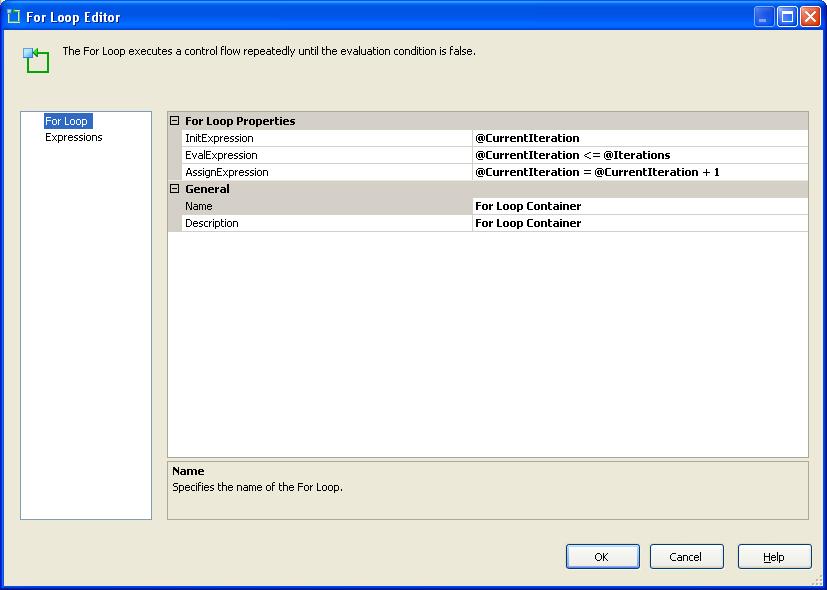
Next drop a For Loop Container into the Control Flow and set it up as below:
Here's a close up of the configuration:
Not the best picture quality so:
InitExpression : @CurrentIteration
EvalExpression : @CurrentIteration <= @Iterations
AssignExpression : @CurrentIteration = @CurrentIteration + 1
Next add an Execute SQL Task into the Loop and set the SQL to:
TRUNCATE TABLE dbo.Modulo_Temp
Now here's the fun part! We will now use the Modulo Algorithm to split the source table into chunks of 10k records. We will treat each 10k chunk as it's own dimension.
You can use the Slowly Changing Dimension task provided with Integration Services, but I prefer the Kimball method one available on CodePlex. It allows a lot more customisation, is faster and works well with this task as you can set your own dimension source using SQL, rather than just pointing to a table in the database. This facet is key as we need to restrict the dimension records to the ones contained within our 10k chunks of each iteration.
Drag a DataFlow component into the ForLoop.
In the DataFlow add an OLE DB Source. Add a variable called 'SourceSQL' with a data type of string. In the properties set 'Evaluate as Expression' to TRUE. In the expression write your select statement for your source table, but add in the Modulo part as below:
"SELECT
Field1,
Field2...
FROM dbo.SourceTable
WHERE (pID % " + (DT_WSTR,10)@[User::Iterations] + ") = " + (DT_WSTR,10)@[User::CurrentIteration] + "
ORDER BY ID
OPTION(MAXDOP 1)"
Next we need to set our Existing Dimension source. Simply modify the code the below to meet your requirements.
/
select
Field1,
Field2...
from dbo.ExistingDimension
where YourBusinessKey in (select ID from dbo.Modulo_Temp)
This code will restict the records in the dimension to only those 10k you pulled through from the source code. Attach your Slowly Changing Dimension task to these two inputs as you normally would and BINGO!!
N.B. Do not use the Delete/Missing outputs from the Slowly Changing Dimension tasks as this will not work. I'll leave you to work out why!
/
Round up of Modulo:
Add (IDField % 5) to split table into 5 chunks. On to this add what part of the table you want like so: (IDField % 5) = 0. It uses zero based index for the chunks.
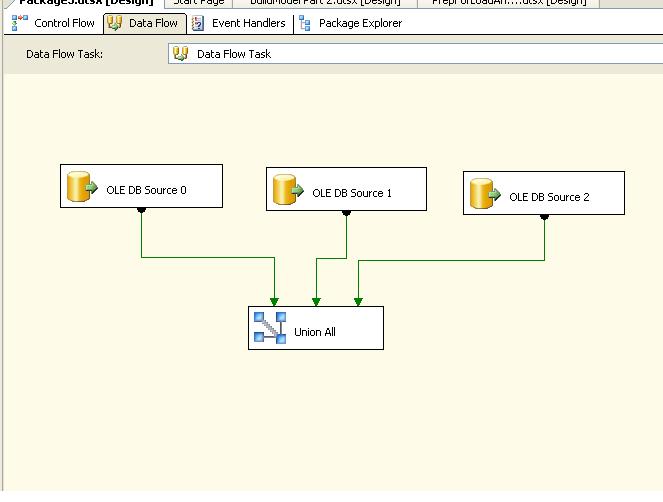
I have also seen this technique used to greatly improve the speed of large imports from SQL. Create 3 OLE DB Sources in one DataFlow, each one taking a third of the table to be imported and union them together. Much faster than one source.
I know this post is quite brief, and skips a few things, but it meant for basic guidance rather than instructions. Always experiement and play around.