Next time I design a large Slowly Changing Dimension I may post it up step by step in greater detail.
With that in mind I thought I'd post a simpler to understand and implement example.
The Algorithm works as follows:
instead of this -
select * from MyLargeTable
Use this query -
select * from MyLargeTable where (ID %3) = 0 OPTION (MAXDOP 1)
The '3' after the percentage sign dictates how many sections to split the table into and the '= 0' dictates which selection we are selecting. It is a zero-based index.
A simple implementation in SSIS looks like this:
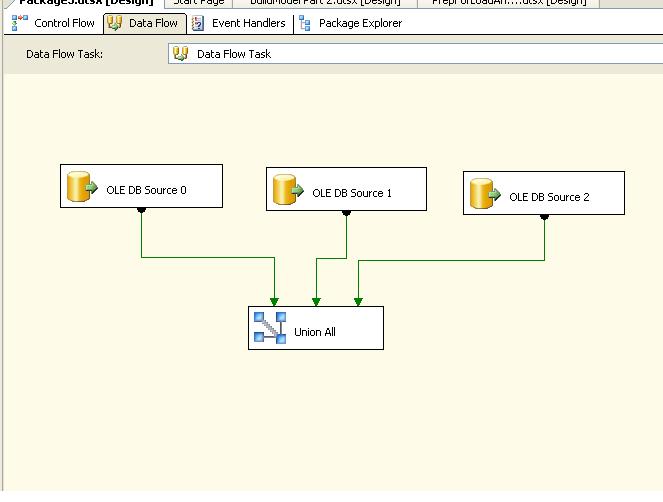
Each OLE DB Source contains the same SQL query as before, but each one uses a different part of the zero-based index (the clue is in the name of the OLE DB Source!).
So there we are - a really simple solution I quarantee will GREATLY improve the speed of large SQL imports, and will also improve the performance of a large dimension when implemented in a bit more context than I had time to write.
N.B. The 'OPTION (MAXDOP 1)' part does something with the processes I can't remember, but I think it's related to running asynchronously and improves performance. Look it up.
No comments:
Post a Comment